
Yesterday, after we saw that the indeni machine have high CPU (this machine has 16 cores), we spent some time profiling indeni collector on one of our coustomers that runs checkpoint devices. Once we were able to setup the profiling tools, we quickly saw that the most expensive CPU operations are IND scripts that parse huge amount (200MB) of data.

The short term solution was to disable some of them (IND script) and increase the interval (and the rule interval) for the others.
Disabled netobj_objects-clustersC.ind and log-server-connection.ind by add do-not-run:"true" to the requires section;
Increase the interval from 5 min to 15 min for vpn-check-tunnels-novsx.ind and vpn-check-tunnels-vsx.ind
Once we applied the changes the CPU consumption dropped from 90%-100% to 5%-30% and spikes to 75% at the 15 min interval
Beside the top 4 expensive IND script we have additional IND scripts that are also consuming a lot of CPU:
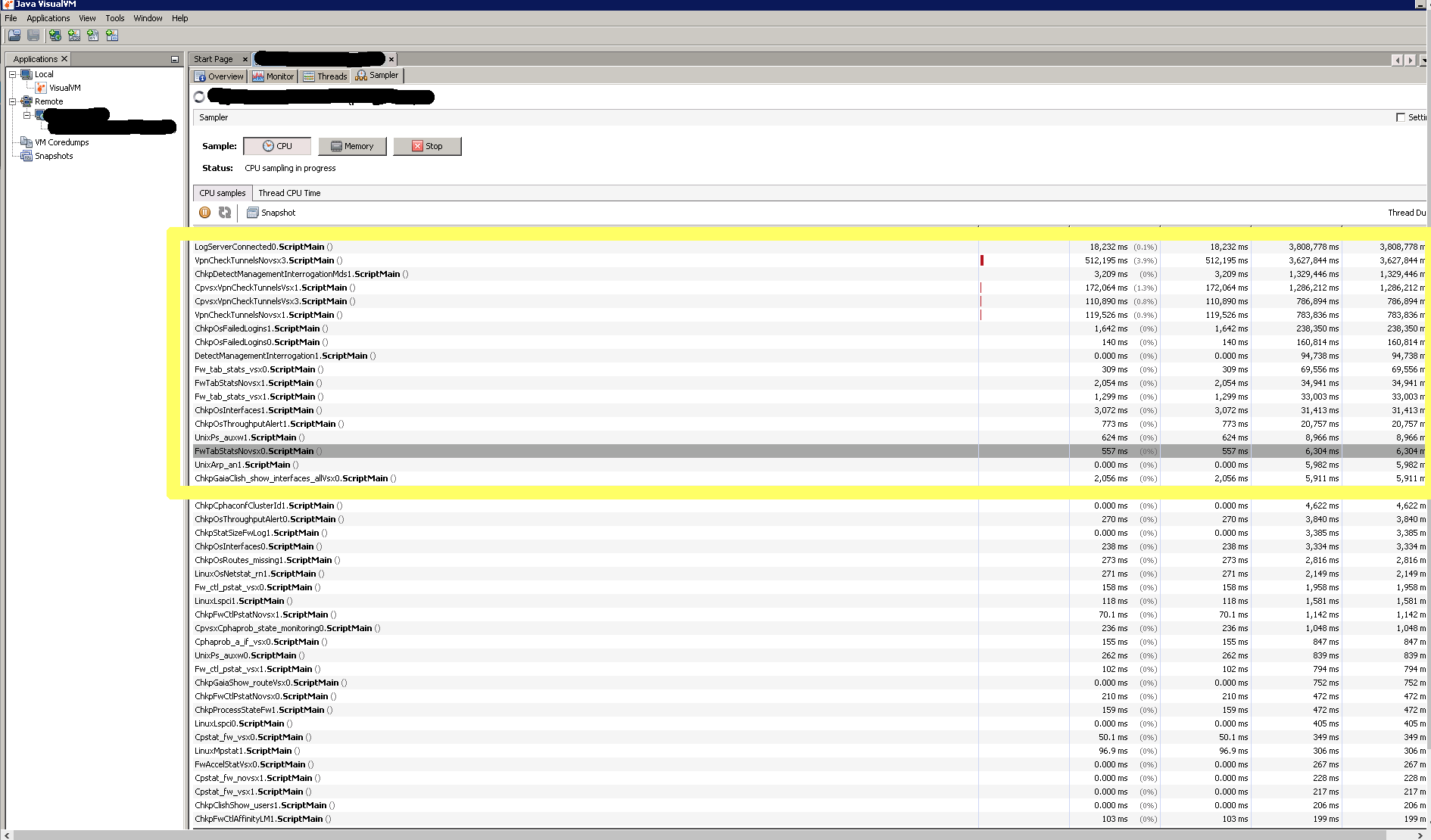
The question to you, knowledge expert is: How and what can we do in order ensure that exisiting and newly added IND script don't choke the CPU (both from the input size that the parser need to handle and the preformance of the parser)
Your thoughts are welcome!
